



版本说明:本文最后更新于
2023-09-18,详细更新记录参见文末表格。若链接或图片失效,对文中内容有任何疑义和勘误意见,欢迎留言反馈。
精选程度:★★★★☆ | 博文状态:已完结 | 本地标签:是
【PyG笔记】基础部分
PyG(PyTorch Geometric)是一个基于PyTorch搭建的用于轻松编写和训练图神经网络(GNN)的库,由斯坦福大学团队开发。除了出色的运行速度外,PyG中也集成了很多论文中提出的方法(GCN,SGC,GAT,SAGE等等)和常用数据集。
【PyG官网链接】https://pyg.org/
【PyG官网文档】https://pytorch-geometric.readthedocs.io/en/latest/
一、安装
1.1、前置依赖
Python版本3.8-3.11、Pytorch库包。
1.2、PyG安装
根据管网安装指南(https://pytorch-geometric.readthedocs.io/en/latest/install/installation.html ),选择合适的版本安装指令安装。

通过pip show命令检查成功安装。
二、基本特性
2.1、图的数据格式
PyG通过torch_geometric.data.Data的一个实例表示单张图,它具有如下属性:
data.x:节点特征矩阵,形状为[num_nodes, num_node_features]。data.edge_index:使用COO格式(Coordinate Format)表示的图中的连接关系,形状为[2, num_edges],类型为torch.long。data.edge_attr:边特征矩,形状为[num_edges, num_edge_features]。data.y:数据标签(可能是任意形状)。例如,节点级别标签形状为[num_nodes, *],图级别标签形状为[1, *]。data.pos:节点位置矩阵,形状为[num_nodes, num_dimensions]。
这些属性都不是必需的。事实上,Data对象甚至不限于这些属性。例如,我们可以通过data.face扩展它,以保存形状为[3,num_faces]的torch.long类型的张量,来表示3D网格中三角形的连通性。
import torch
from torch_geometric.data import Data
edge_index = torch.tensor([[0, 1, 1, 2],
[1, 0, 2, 1]], dtype=torch.long)
x = torch.tensor([[-1], [0], [1]], dtype=torch.float)
data = Data(x=x, edge_index=edge_index)
>>> Data(edge_index=[2, 4], x=[3, 1])
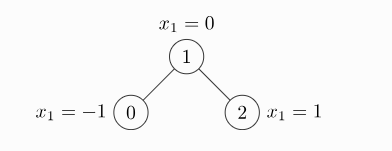
Data类还提供了一些有用的通用函数,例如
print(data.keys())
>>> ['x', 'edge_index']
print(data['x'])
>>> tensor([[-1.0],
[0.0],
[1.0]])
for key, item in data:
print(f'{key} found in data')
>>> x found in data
>>> edge_index found in data
'edge_attr' in data
>>> False
data.num_nodes
>>> 3
data.num_edges
>>> 4
data.num_node_features
>>> 1
data.has_isolated_nodes()
>>> False
data.has_self_loops()
>>> False
data.is_directed()
>>> False
# Transfer data object to GPU.
device = torch.device('cuda')
data = data.to(device)
2.2、通用基准数据集
PyG包含大量的通用基准数据集。
初始化数据集很简单。数据集的初始化将自动下载其原始文件,并将它们处理为前面描述的 Data 格式。例如,要加载 ENZYMES 数据集(包含6个类中的600张图)。
from torch_geometric.datasets import TUDataset
dataset = TUDataset(root='dataset', name='ENZYMES') # 存储在当前文件夹的dataset文件夹下
>>> ENZYMES(600)
len(dataset) # 数据集包含600张图
>>> 600
dataset.num_classes # 图的类型有6种
>>> 6
dataset.num_node_features
>>> 3
现在,我们即可查看数据集中的任何一张图。
data = dataset[0]
>>> Data(edge_index=[2, 168], x=[37, 3], y=[1])
data.is_undirected()
>>> True
数据还可能包含train_mask, val_mask和test_mask等各种属性,例如:
from torch_geometric.datasets import Planetoid
dataset = Planetoid(root='dataset', name='Cora')
>>> Cora()
len(dataset)
>>> 1
data = dataset[0]
>>> Data(edge_index=[2, 10556], test_mask=[2708],
train_mask=[2708], val_mask=[2708], x=[2708, 1433], y=[2708])
data.train_mask.sum().item()
>>> 140
data.val_mask.sum().item()
>>> 500
data.test_mask.sum().item()
>>> 1000
train_mask表示要对哪些节点进行训练(140个节点)val_mask表示要使用哪些节点进行验证(500个节点)test_mask表示要对哪些节点进行测试(1000个节点)
2.3、批处理
torch_geometric.data.Batch继承自torch_geometric.data.Data并且具有一个附加属性batch。
batch 是一个列向量,用于将每个节点映射到批次中相应的图:
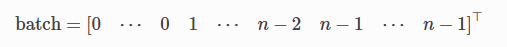
from torch_geometric.datasets import TUDataset
from torch_geometric.loader import DataLoader
dataset = TUDataset(root='dataset', name='ENZYMES', use_node_attr=True)
loader = DataLoader(dataset, batch_size=32, shuffle=True)
for batch in loader:
batch
>>> DataBatch(batch=[1082], edge_index=[2, 4066], x=[1082, 21], y=[32])
batch.num_graphs
>>> 32
2.4、数据转换
Transforms是torchvision变换图像和执行增强的常用方法。PyG 提供自带的Transforms,将Data对象作为输入,并返回一个新的变换后的Data对象。可以使用torch_geometric.transforms.Compose 将Transforms串联起来,并在将处理过的数据集保存到磁盘之前(pre_transform)或访问数据集中的图之前(transform)应用这些变换。
例如,在 ShapeNet 数据集(包含 17,000 个三维形状点云)上应用Transforms。
from torch_geometric.datasets import ShapeNet
dataset = ShapeNet(root='dataset', categories=['Airplane'])
dataset[0]
>>> Data(pos=[2518, 3], y=[2518])
我们可以通过Transforms从点云生成近邻图形,从而将点云数据集转换为图数据集。(此步在我的实验中报错,可能是PyG或Pytorch的版本等原因)
import torch_geometric.transforms as T
from torch_geometric.datasets import ShapeNet
dataset = ShapeNet(root='dataset', categories=['Airplane'],
pre_transform=T.KNNGraph(k=6))
dataset[0]
>>> Data(edge_index=[2, 15108], pos=[2518, 3], y=[2518])
此处使用
pre_transform在将数据保存到磁盘之前对其进行转换(从而加快加载速度)。请注意,下一次初始化数据集时,即使不传递任何Transforms,数据集也已包含图的边。如果pre_transform与已处理数据集中的pre_transform不匹配,系统将发出警告。此时需要先删除相应数据集下的
processed文件夹。
2.5、图学习方法
我们将使用一个简单的 GCN 层,并在 Cora 引用数据集上进行实验。
from torch_geometric.datasets import Planetoid
dataset = Planetoid(root='dataset/Cora', name='Cora')
>>> Cora()
简单实现一个两层的GCN。
import torch
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
class GCN(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = GCNConv(dataset.num_node_features, 16)
self.conv2 = GCNConv(16, dataset.num_classes)
def forward(self, data):
x, edge_index = data.x, data.edge_index
x = self.conv1(x, edge_index)
x = F.relu(x)
x = F.dropout(x, training=self.training)
x = self.conv2(x, edge_index)
return F.log_softmax(x, dim=1)
让我们在训练节点上训练这个模型,执行200个epoch。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = GCN().to(device)
data = dataset[0].to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01, weight_decay=5e-4)
model.train()
for epoch in range(200):
optimizer.zero_grad()
out = model(data)
loss = F.nll_loss(out[data.train_mask], data.y[data.train_mask])
loss.backward()
optimizer.step()
最后,我们可以在测试节点上评估我们的模型。
model.eval()
pred = model(data).argmax(dim=1)
correct = (pred[data.test_mask] == data.y[data.test_mask]).sum()
acc = int(correct) / int(data.test_mask.sum())
print(f'Accuracy: {acc:.4f}')
>>> Accuracy: 0.7980
Q & A
暂无
更新记录
| 时间 | 修改内容 |
|---|---|
| 2023-09-18 | 首次发布版本 |
评论区